 ディープラーニングは、なぜ、自然言語処理で失敗したのか
ディープラーニングは、なぜ、自然言語処理で失敗したのか
【マインド・エンジン】絶対不可能といわれていたコンピュータによる言葉の意味理解。ついに成功したので公開します。
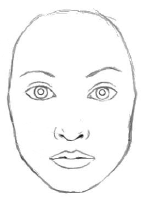
この画像は、人間の顔ですよね。
誰でもわかります。
最近のAIなら、100%の確信を持って「人間の顔」と答えます。
ディープラーニングのすごいところです。
では、次の画像はどうでしょう?
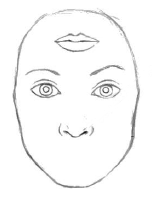
「人間の顔っぽいけど・・・、こんな人間いませんよ」
そうですよね。
明らかにおかしいです。
おでこに口があります。
こんな人間いません。
断言できます。
でも、ディープラーニングで学習したAIに画像認識させると、これも、ほぼ100%の確信をもって「人間の顔」と答えるのです。
どこかおかしいなんて、微塵も感じないようです。
参考:http://img2.iyiou.com/Editor/image/20180225/1519566625670442.pdf p19 8.The emergence of ‘capsule networks’
https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
なぜ、こんなことが起こるのでしょうか?
これが、ディープ・ラーニングの盲点なのです。
「ディープラーニングは、なぜ、自然言語処理で失敗したのか?」で説明したように、ディープラーニングでは、大量の画像から自動で特徴量を抽出します。
たとえば、猫の画像があれば、まず、耳や目、鼻、口などのパーツに分類し、耳の形などの特徴から、猫と判断するわけです。
何十万枚の大量の画像があれば、犬や、他の動物とは違う、猫の特徴を抽出できるのです。
耳の形や顔の形、しっぽ、体の大きさから犬か猫かを判断するところは、まさに、人間と同じです。
これが、ディープラーニングのすごいところです。
でも、人間は、額に口がある画像を見て、明らかにおかしいと思いますよね。
なぜ、こんなに簡単なことが、AIはわからないのでしょう?
ディープラーニングに限らず、機械学習では、統計を使いますので、大量のデータが必要となります。
データの数が少ないと、偏りが生じてしまうからです。
何百万枚もの人間の顔画像のデータがあれば、人間の顔を見分けるのに十分なデータといえるでしょう。
ところが、落とし穴はここにあります。
現実に存在する顔写真のデータを何百万枚、何千万枚集めても、その元データ自体に偏りがあるのです。
どういうことかというと、人間の顔は、目の下に鼻があって、鼻の下に口があって、目の上に額があります。
何千万枚の顔写真を集めても、額に口がある写真は存在しません。
顔の正しいパーツの位置を機械学習で学習させるには、顔のパーツのあらゆる位置の組み合わせの画像データが必要になります。
そのうち、正しい組み合わせがこれだと教えることで、顔のパーツの正しい位置が学習できるのです。
ところが、たとえ、全人類の顔写真を集めたとしても、あらゆる顔パーツの位置の組み合わせのデータが得られるわけではありません。
すべての人類は、鼻の下に口があって、目の上には口はありません。
つまり、現実世界のデータをすべて集めても、あらゆる方面から検討しても偏りのないデータを集めることは不可能なのです。
AI業界では、大量のデータさえ集めれば、あとは、ディープラーニングが自動で学習してくれるという風潮がありますが、実際には、現実世界のすべてのデータを集めたとしても、現実世界自体が偏っているため、最適に学習することができないのです。
その結果、人間なら、簡単におかしいと思う、あり得ない顔を見ても、AIには、永久にそれを見抜けないのです。
これが、現在のディープラーニングの限界なのです。
この傾向は、画像認識より、自然言語処理でより鮮明に表れます。
次回は、そのことについて説明します。
YouTubeでは、さらに本質をかたってます



ロボマインド・プロジェクトの最新情報はYouTubeで!








「100%自信を持って」というのはいかがなものか。
おでこに唇があれば、(del(出力値)/del(おでこの部分の色の濃さ)などがマイナスになるよう学習されることから)
明らかに人間の顔に相当する部分の出力値が下がり、softmax適用後の値が下がる。
いうなれば、「これは人間である」という確信度が下がることになる。
ディープラーニングでも不信感を持つのだ。
ブログで不完全な知識をもとに醜態をさらす前に、まずは一度機械学習について一から勉強してみてはいかがだろう。
見ているこちらが恥ずかしい。
>「これは人間である」という確信度が下がることになる。
そこに閾値を入れてチューニングするのは、AI 駆動のシステムを仕上げるという点ではかつては実践的。実際、自分も周りもやっていた。けど、どっちかというとそれは 10 年以上前の話で、アナクロな方法になりつつある。
というのは、理論面では「じゃあ AI は閾値を疑うことができるの?」という問題が追っかけてくる。自分はこれはゲーデルの不完全性定理を鑑みると、AI には無理と予想している。
これに対する現代的な答えは「正例も負例もガンガン学習させてしまえ。パーツの空間構造が重要な情報であれば、マトモな学習アルゴリズム (== 最大エントロピー原理を満たすヤツ) さえあれば行けるはずだ。あとは教師データの質だ」。これの意味するところは「未知事象をなくしてしまえば、未知事象に起因する問題もなくなる」。ビッグデータや並列処理などが使える現代ならでは。昔は無理だったけど、昔 AI をやってた人がその足かせに気づいてないことが多い。
まぁ、これは同時に「ビッグデータを手にしたものが勝者」でもあるわけで、AI で食っている会社が肥大化する原因でもあるんだけど。特に「どのデータがモデリングに最も寄与しているか?」はこのやり方では追求しにくいんで、教師データの選別はやりにくくなる。
部分の集まりが全体であるというような粗雑で幼稚な認識方法をAIは取っているのですか?それでは決してインテリジェンスとは言えませんね。
はい、そうなんです。
現状のディープラーニングで獲得できることは、まだ、この程度のことなのです。
それでも、教えなくとも自動でここまで獲得できるのは、それはそれで、すごいことなのですが。
人が顔を認識できるようになるまでのプロセスを考えると、全体の印象だけではなく、顔の各部分の動きだったりを通じて、部分認識も行い、さらには配置の特徴など通常のディープラーニングでの顔認識での訓練量を遙かに凌駕する量の訓練を行っています。訓練量もコストなので、現状は非常に絞り込んだ少ない訓練量でも、うまく訓練すればまあまあの性能が出る、という分野から応用されているのであって、手抜きした部分を突かれればいくらでもボロが出るのは当然です。クラウドの仕事が買いたたかれているのを見ると、人の脳の方が安く手に入る状態が続くと思っています。そうなるとAIが単独で人の能力を全て超えるて脅威になるより先に、人間の脳+ICTを連動させてHyper脳とする方向が新たな脅威、例えば、Hyper脳を有する人々が人格のATフィールド的なものを溶解させてしまって、複数個体にまたがる人格を発生してしまうことなどの脅威を生み出すのではないかと個人的には思っています。
コメント、ありがとうございます。
Hyper脳の話、確かにありそうですね。
脳内で、意識がイメージしている世界に直接アクセスすることができるようになれば、他人の意識が見ている世界を直接見たりできると思います。
そうなれば、Hyper脳の可能性も出てきますね。
脳で直接人類が繋がるようになれば、世界が一体となる真の平和が訪れるのか、別の脅威が生まれるのか。
いずれにしても、人類が経験したことのない新たなステージに進むでしょうね。
ディープラーニングの限界っていうよりAI全般が抱える課題で、いわゆるフレーム問題やシンボルグラウディング問題に近い話ですよね。
AIに
「目の下に鼻があって、鼻の下に口があって、目の上に額があり画像は人間」
「目の下に鼻があって、目の上に口がある画像は人間ではない」
と教えたとして、今度は
「目の上に鼻があって、鼻の下に口があって、目の上に額があり画像」をAIが適切に判断できない可能性が出てくる。
どこまで教えこめばいいねん!
って話だと解釈しました。
ちなみに分類は無理かと思いますが、「人間か否か」の課題であればDeepLearningのAutoEncoderモデル(教師なし学習)で解決できるかもしれないですね。
正常な人間の画像だけで学習させたモデルを作り、入力された画像が正常な人間の画像とどれぐらい違うのかをスコアとして出力するAIモデルにして、閾値を設定すれば…。
まぁ、設定する閾値や訓練で使用する画像データにも依存しそうですけどね
もっぱー様
コメント、ありがとうございます。
そうなりますよね。
人間の顔を、画像でしか判断してないから、こんなことになるのですよね。
目は細くなったり丸くなったりするのは有りだけど、鼻の下に移動するのは絶対にあり得ないってことは、人間ならだれでもわかります。
それは、自分が顔をもっていて、自分の目が細くなったり丸くなったりするのは経験するけど、鼻の下に移動することは経験したことも、見たこともないからです。
その身体感覚があるから簡単にわかるわけです。
ところが、画像認識するAIは、目を細くしたり丸くしたりするのも、鼻の下に移動するのも、処理コストはあまり変わらず、違和感を感じないわけです。
大量の顔画像データから、目や鼻のパーツの位置情報も学習させたら、鼻の下に目があるのは異常だと検出することはできるようになるでしょうね。
でも、それはパーツの位置を学習しただけで、顔の意味や、目や鼻の意味を理解したわけじゃないので、今のAIが抱える本質的な問題の解決には至らないですね。
[…] プラーニングは、なぜ、こんな簡単な画像認識もできないのか?https://robomind.co.jp/deeplearninghanazegazouninsikidekinai/ […]
都合の悪い反論に対してただ煽ることしかできないんですか?
fjordyさんのコメントとそれに対するリプライについてです。
彼の反論は論理的であり主張としては真っ当です。
問題は彼の反論の是非についでではなく、真っ当な反論を煽るだけで無視するというあなたの行為です。
真っ当な反論を煽るだけで無視することは現実の無視と同義です。
さすがに言わなくてもわかると思いますけど、現実の無視は実現不可能への道ですよ。
このプロジェクト実現のためにも、正当な反論をしてもらえませんか?
失礼かもしれませんが、深層学習の仕組みをおおまかに理解されるとプロジェクト成功への道へ進路を近づけることができるのではと思います。
※中2なんで、文おかしいとこがあるかもしれません。
に対してただ煽ることしかできないんですか?
fjordyさんのコメントとそれに対するリプライについてです。
彼の反論は論理的であり主張としては真っ当です。
問題は彼の反論の是非についでではなく、真っ当な反論を煽るだけで無視するというあなたの行為です。
真っ当な反論を煽るだけで無視することは現実の無視と同義です。
さすがに言わなくてもわかると思いますけど、現実の無視は実現不可能への道ですよ。
このプロジェクト実現のためにも、正当な反論をしてもらえませんか?
※中2なんで、文おかしいとこがあるかもしれません。
※課題の目途が立ってきたと代表プロフィールページにありますが、よろしければ聞かせてもらえませんか?