 言葉の意味をどう定義するか
言葉の意味をどう定義するか 言語世界と仮想世界
言語世界と仮想世界 感情とは 認知パターンって何?
感情とは 認知パターンって何? 絶対に超えられないディープラーニング(深層学習)の限界
絶対に超えられないディープラーニング(深層学習)の限界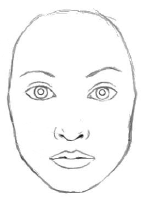 ディープラーニングは、なぜ、こんな簡単な画像認識もできないのか?
ディープラーニングは、なぜ、こんな簡単な画像認識もできないのか?
【マインド・エンジン】絶対不可能といわれていたコンピュータによる言葉の意味理解。ついに成功したので公開します。
現在は第3次AIブームと呼ばれ、その主役は、ディープラーニング(深層学習)です。
ディープラーニングは、学習によって自動で特徴量を抽出できるため、大量のデータを入力さえすれば、勝手に賢くなると思われています。
そこで、一時は、大量の会話データを入力すれば、自動で会話できるようになるかと思われていましたが、実際は、そうはなりませんでした。
それでは、なぜ、ディープラーニングは、会話、自然言語処理に対応できないのでしょう?
まずは、簡単にディープラーニングのおさらいをしておきましょう。
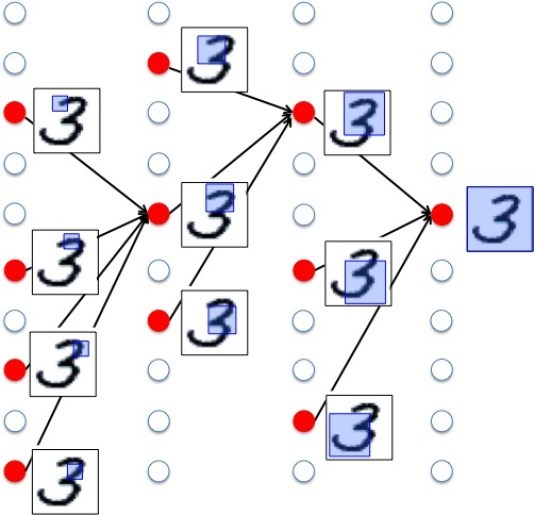
たとえば、手書きの数字を認識できるシステムを考えてみましょう。
そのために学習するデータとして、大量の手書きの数字を用意します。
そうしてディープラーニングで学習させると、自動で特徴量を抽出し、手書き数字を認識できるようになります。
ディープラーニングの構造は、入力層と出力層の間に多数の隠れ層が存在する多段階のニューラルネットワークです。
この隠れ層で、特徴量を認識します。
特徴量とは、手書き数字の場合、文字の端が真っすぐか曲がっているかとか、全体が丸いか棒状かといったものです。
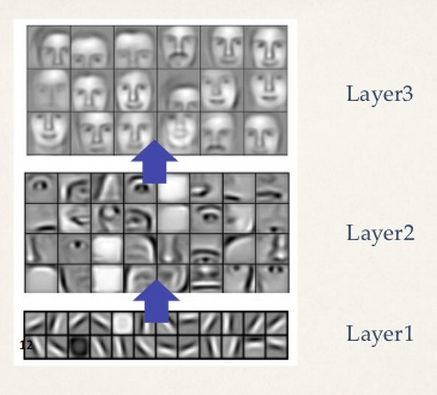
浅い層では、部分的な小さい特徴を抽出し、深い層では、全体像を抽出します。
入力された画像を小さい部分の特徴から見ていき、徐々に大きな部分を見て、最後に、全体的な特徴を見て入力画像を認識します。
文字認識だけでなく、一般的な画像認識でも同じで、浅い層では、たとえば目や耳や鼻などの部分部分の特徴を見て、深い層では全体像を見て「人の顔」と認識します。
これは、人間が頭の中で行っている処理とよく似ています。
1000万枚の画像を学習することによって、人が教えることなく、猫を認識できるようになったグーグルの話は有名です。
その時獲得した最も猫らしい猫が以下の写真です。

これは、いってみれば、猫の概念と言えます。
ディープラーニングの特徴は、データから自動で特徴を抽出してくれることですが、どんなデータを入れてもいいわけではなく、認識させたい内容に応じた適切なデータを入力しないといけません。
手書き数字を認識させたいなら、大量の手書き数字を学習データとして入力します。
顔認識したいなら、顔が写った大量の写真を入力しないといけません。
さて、大量の写真から、犬や猫を認識できるようになりました。
これは、自然言語で言えば、「名詞」を抽出したと言えます。
猫を抽出できる学習済みのニューラルネットワークは、浅い層では、「とがった耳」とか「ひげ」を認識します。
これは、「猫」は「とがった耳」「ひげ」を持つと言えます。
これは、ロボマインド・プロジェクトで言えば、has-aに該当します。
また、深い層で認識する「猫」の全体像は、頭と胴と4本の足としっぽを持ちます。
このような部品を持つ同じ層には、「犬」とか「ライオン」とかがいて、近い仲間と認識します。
これは、ロボマインド・プロジェクトで言えば、概念ツリーの中の動物概念に該当するとも言えます。
このように、ディープラーニングの学習で獲得したものは、ロボマインド・プロジェクトのHas-aの概念と同種のものと言えます。
(ロボマインド・プロジェクトのHas-aと概念に関しては、「言葉の意味をどう定義するか」を参考にしてください)
「名詞」が獲得できれば、次は、「動詞」です。
それでは、「動詞」を抽出するにはどうすればいいでしょうか?
例えば、「歩く」の場合を考えてみましょう。
人が「歩く」といって思い浮かべるイメージは、静止している状態でなく、足を交互に動かし移動している状態です。
となると、「歩く」を認識させるには、静止画でなく動画が必要になります。
大量の歩いている動画を学習させれば、「歩く」の概念が獲得できるでしょう。
おそらく、そこには、交互に動かす足とか、移動といった概念が特徴として抽出されているでしょう。
おそらく、近い将来、このようにして動詞の概念も獲得できるようになるでしょう。
言葉というのは、人間の頭の中のイメージを表現したものです。
自然言語処理といっても、学習データが言葉だけでは、人がイメージするのと同じイメージを獲得することはできません。
言葉の背後にある概念を獲得するには、現実世界にある物の写真や動画で学習する必要があるのです。
そして、学習した概念に「猫」とか「歩く」といったラベルを貼るのです。これが言葉です。
名詞や動詞の概念が認識できれば、次は、「文」です。
「文」とは、名詞や動詞から成り立ちます。
「文」を認識するとは、ディープラーニングで学習した名詞や動詞の概念を使って文を組み立てることになります。
「猫が歩く」という文なら、「猫」の概念に、「歩く」の概念を当てはめて、猫が歩く様子を作り上げます。
おそらく、それは、猫が歩く3DCGのイメージになるでしょう。
これは、まさに、ロボマインド・プロジェクトの仮想世界、そのものです。
(ロボマインド・プロジェクトの仮想世界に関しては、「言語世界と仮想世界」を参考にしてください)
「文」が表現できれば、次は、「その文は、何を言いたいか」という文の意味の抽出です。
「何がいいたいか」とは、ロボマインド・プロジェクトでは、認知パターンを抽出することと同じです。
たとえば、「欲しかったものが手に入って『嬉しい』」とか、「先生に怒られて『悲しい』」といった、どの感情(認知パターン)に該当するかから、話し手が言いたいことを抽出します。
(認知パターンに関しては「感情とは 認知パターンって何?」を参考にしてください)
ディープラーニングでこれをするとすれば、ディープラーニングで学習した概念で構成した文の世界を大量に用意し、それを学習させることで、いくつものパターンを抽出させます。
たとえば「価値のある物をもらって『うれしい』」といったパターンとか、「それをくれた人に『感謝』した」といったパターンです。
このようなパターン抽出は、ディープラーニングの最も得意なところです。
ここまで見てきて、ディープラーニングが、なぜ、自然言語処理に失敗したのか、少し分かってきた気がします。
それは、大量の文書データを読み込ませて、一気に学習させたからです。
正しいやり方は、段階を追って学習させることです。
つまり、何を認識させたいか。
それを明確にして、適切なデータを使って、段階的に学習させればディープラーニングでも自然言語処理を扱うことは可能です。
むしろ、人がルールを教えるより、より効果的に学習できるはずです。
ディープラーニングで効果的に自然言語処理ができるなら、人がルールを教えるタイプのロボマインド・プロジェクトの意義は何でしょう?
それは、どのような手順で自然言語を学習すべきかといった指標を示し、そのプロトタイプを作成することです。
開発ロードマップといってもいいかもしれません。
名詞、動詞を学習したら、次は、それを使った文を仮想世界上に構築し、その次は、仮想世界から認知パターンを抽出するといった開発の道筋を示すのがロボマインド・プロジェクトの役割だと思っています。
そして、最終的には、自然言語においてもディープラーニングが最も適切に処理できると思います。
名詞や動詞だけでなく、認知パターンも、人が作成するより、ディープラーニングで抽出したほうが、人が気付かない隠れた認知パターンを発見できると考えています。
20年ほど前、「逆切れ」という言葉が流行りました。
これは、怒られているのに、怒られている人が逆に怒り返すというおかしな行動です。
意識したことはなかったですが、言われてみれば、たしかに、そんな光景はよくみます。
初めて聞いた時、「うんうん、確かにそういう人いる!」と、この言葉にひどく納得したのを覚えています。
これが、隠れた認知パターンの発見の一例です (発見したのは松本人志とのことです)。
逆切れしてくるAIロボットがいれば、かなり人間臭いですしね。
たとえば、ロボットが人間に手を出して処罰されたとき・・・
「ロボット工学3原則なんて、人間からの一方的な押し付けちゃいますの!」
「ロボット側の言い分を全然聞かんと、ロボットが殴ったらアカンわって、そればっかり責めますやん・・・
そんなん言うんやったら、そもそも、なんで、AIロボットなんか作ったんやって話になりますやん・・・」
続きは、YouTubeで語っています。




ロボマインド・プロジェクトの最新情報はYouTubeで!








素晴らしい。ディープラーニングによって色々な特徴が掴めてくれば、新しい概念や言葉も作られてきますね。動物との会話もできそうですね。
ありがとうございます。
心のモデルが完成して、それにディープラーニングを適用すれば、さまざまな概念が見つかると思いますよ。
[…] わって、そればっかり責めますやん・・・ そんなん言うんやったら、そもそも、なんで、AIロボットなんか作ったんやって話になりますやん・・・」 https://robomind.co.jp/deeplearninghanazesippai/ […]
5〜6年くらい前だと思うのですが、いっちょ面白い自然言語のインタプリタを有したデータベースを作ってやろうと思ったことがありました。AIの研究はかなり古典的なものなので、すでにライブラリがたくさん存在しているはずだから、それらを適当に組み合わせたらWebをクローリングして知識を収集し、それを組み合わせて回答を生成できるシステムなど簡単にできるだろうとおもったわけです。ところが、現実問題、自然言語の処理というのは思いの外大変で、結局は断念した。
この記事に限らず、ブログの中で何度かワトソンについて言及されていますが、当時僕が調べた限りでは、ワトソンの構造はいわゆる人工無脳とは全く違っているように思えます。
参考:https://www.ibm.com/blogs/solutions/jp-ja/watson-machinelearning-1/
別にIBMの肩を持つわけではないですが、この簡単な説明を見る限りでも、「メタデータ」と呼ばれるある種のオントロジーを持ったデータベースとなっているようです(新しい治療法の発見、レシピの生成、などの機能が実現できたのはこのためだと思われます)。ブログ主さんが、どの程度のシステムを開発しようと考えているのかはわかりませんが、いわゆるAIの分類としてはIBMワトソンにかなり近いように思われます(単語をベースとした、概念のデータベースを持ち、そこからパターンを抽出するというような構成)。ワーキングペーパーなども公開されているようなので、ちょっと読んで見たらいいのでは、と思います。
その頃僕が興味を持っていたシステムが他にもあります。下記のものです。
https://research.preferred.jp/2011/07/markov-logic/
これはAIというか処理系ですが、自然言語をベースとした推論を行う、という目的を考えるとかなり参考になりそうなものだと思います。述語論理ベースの推論システムというとかなりクラッシックな香りがしますが、インターネットから自動で知識を収集することで、「知識を人間がメンテしなければならない」という、初期のエキスパートシステムの問題点を解決しようとしているものもあり、個人的には頑張って欲しいなぁ(?)と思ったりもしています。
http://www.anthology.aclweb.org/D/D10/D10-1106.pdf
結局、普通の人がAIと聞いて思い浮かべるのは、「対話的に質問に答えてくれること」のような気がします(そういう映画を見て育った世代だからかもしれませんが)。確かに、「感情」や「共感」といった側面も必要かもしれませんが、単純な推論を行い、それについて説明することができる、というだけでも、自然言語をインターフェーイスとしたシステムとしては画期的で、感情や意識といった高次の機能は、収集した知識から「エミュレート」する形で実現するしかないんじゃないかなぁ、という気もします(コンピュータに意識を持たせるというのは、ざっくり言って無理なのでないかなぁ、というのが私の意見ということ)。
「ロボマインド・プロジェクト」これからどうなるのだろう?思ってしまうところもありますが、どうせ新しいことをするなら、目標は高い方がいいのかもしれませんね!ニューラルネットワークを応用した人工知能がAIブームを牽引しているように見えますが、自然言語をコンピューターに理解させる、というのはチューリングがチューリング・テストを提唱して以来の、見果てぬ夢なので、実現できたらすごいと思います!
通りすがりさん、コメントありがとうございます。
コメントを読む限り、かなりAIに詳しい方のようですね。
たしかに、おっしゃるようにワトソンは、単純な人工無脳と同じとは言い切れないところはあると思います。
僕が取り組んでいるロボマインド・プロジェクトは、最終的な形態がワトソンのような対話プログラムに近い物なので、ワトソンと同じようなものと思われるのも無理がないかもしれません。
また、技術的には、概念といったオントロジーを使っているもので、そう誤解されるのかもしれませんし、AIに詳しいと、エキスパートシステムと比較したくなるかもしれません。
そうなんですよね。
AIに詳しければ詳しいほど、「推論」「オントロジー」「エキスパートシステム」「人工無脳」といった今まであった知識のどれかに当てはめようとして、そのどれにも当てはまらないと、無理なんじゃないかなぁと思って、それ以上深く考えなくなるようです。
僕が提唱している根本的な理論は、「意識の仮想世界仮説」で、これは、今までのAIとは全く異なるところから出発しています。
表層に近い部分で、オントロジーを使っているので、AIの知識のある人は、その部分しか見ない傾向があるようですが、メタデータのようなオントロジーなんかは、誰が考えてもそうなるわけで、僕にとっては、そんなとこは、正直、どうでもいい話なんですが。
最も重要な「主観」だとか「意識」といった部分は、技術者の苦手な分野に属するようで、みなさん、スルーされます。
逆に、哲学が好きなひとは、「主観」や「意識」に関するブログにコメントを寄せてくれます。
もし、通りすがりさんが、AIという枠を取り払って、本当に、コンピュータに意識を持たせる方法に興味があるなら、ぜひ、以下のブログを順に読んでみてください。
ロボマインド・プロジェクトとは
「ロボットの心」を作るってどういうこと?
感情とは 認知パターンって何?
チューリング・テストと心の仕組み(心のエコシステム)
そもそも意識って何?人工知能で人工意識は作れるの?
主観と客観
3次元空間を認識するってどういうこと?
記憶って何?思い出ってどういうこと?
時間は現実には存在しない。時間は幻想。
意識の仮想世界仮説 -目の前に見えてる世界は全て幻想-
意識をプログラムで作るには
ロボマインド・プロジェクト システム概要
通りすがりさんが、全く新しいアイデアを受け入れる勇気を持っていることを祈っています。
『人工知能は人間を超えるか』のディープラーニングからの技術進展で
ディープラーニングが以下のように進歩すると予測されています。
これが実現できれば失敗とは言えないのでは?
いかがでしょうか?
①画像特徴の抽象化ができる A I → ②マルチモ ーダルな抽象化ができる A I
③行動と結果の抽象化ができる A I
④行動を通じた特徴量を獲得できる A I
⑤言語理解 ・自動翻訳ができる A I
⑥知識獲得ができる A I
karat様
コメントありがとうございます。
記事のタイトルの「ディープラーニングは、なぜ、自然言語処理で失敗したのか」は、いわゆる「釣りタイトル」で、本気で失敗したと主張したいわけではないです^^;
ディープラーニングで意味理解ができるようになれば、そりゃ、すごいと思いますよ。
AIは大きくコネクショニズムと記号主義に分かれて、ディープラーニングはコネクショニズムに属して、僕の手法は、どちらかと言うと記号主義に属します。
ディープラーニングが得意なのは、大量のデータから最適解を求めることですが、最適解となるルール自体はディープラーニングで作り出すことはできません。
画像認識で、ネコや犬を認識できるようになっても、2次元画像からネコや犬の3次元を生成することは、そのルールを教えない限り、いくら大量のデータを与えても、自動でできるようにはなりません。
ルールはあくまでも人間が考えて与えないとできません。
ルールを作るのが記号主義となるわけです。
大雑把なルールが完成すれば、次は、大量のデータを与えて自動で最適化するというのが、AIの流れになると思います。
この辺りのことは、「『教えて!いろはちゃん』全文掲載」で分かりやすく説明してますので、ぜひ、読んでみてください^^
>ディープラーニングで意味理解ができるようになれば、そりゃ、すごいと思いますよ。
もし、意味理解ができるまでになれば
そのAIは意識を持っているのでしょうか?
ディープラーニングだけで意識は作り出せますか?
このディープラーニングモデルには仮想世界のモデルは持っているのでしょうか?
karat様
コメント、ありがとうございます。
「意識」というのは、人によって定義すら変わってくるものでして、意識の話をする場合はそこを気に掛ける必要があります。
意識科学の分野でいう意識は、眠っている間はなく、起きている間にある意識を指して、人間だけでなく、動物にもあるものを指しているようです。
IITなどで使ってるのは、この意味での意識ですね。
僕の言う意識は、もっと限定されたもので、人間のみが持ちうるものを指してます。
具体的には、言語を使える能力があるものを意識と呼んでいます。
そこで、言葉の意味理解ができるなら、僕のいう意識は備えていると考えます。
ディープラーニングで学習させるには、学習するモデルが先に合って、そのモデル内で最適なパラメータを学習させるわけです。
今のところ、ディープラーニングで学習させるモデルに、仮想世界のモデルは聞いたことはないです。
ディープラーニングを使った自然言語処理では、概念を使って言葉をまとめたりましています。
後は、文章の一部の単語を隠して、それを予想させるといった学習を繰り返すといったことをやっているみたいですね。
隠された単語を当てるゲームで、人間に勝ったことで人間より意味理解ができるようになったと言っているようですが、それで意味理解できてるというのは、ちょっと早計じゃないかと思いますよね^^;