 Why Has Deep Learning Failed in Natural Language Processing?
Why Has Deep Learning Failed in Natural Language Processing? 自然言語処理って、こんなこともわからないの?
自然言語処理って、こんなこともわからないの? What Are Emotions ? What is A Cognitive Pattern?
What Are Emotions ? What is A Cognitive Pattern?
Important Factors Learnt from Helen Keller which Today’s Natural Language Processing Lacks of 1
What deep learning can and cannot do
Amongst the AI hype, people continue to believe that deep learning can do anything better than us humans. However, we need to be aware that deep learning has its limit and cannot exceed human’s abilities.
Which is, language comprehension (natural language processing).
Now, let me explain where lies the limit of deep learning and how we can make AIunderstand human language in this chapter.
First let’s briefly go back again to the basic concept of deep learning using the example of hand-written numbers recognition as a reference.
Features of hand-written numbers are: overall round or straight lined, partially round or with several circles, a complete circle or an incomplete circle.
To identify numbers, we use these feature values as a judgement point.
When you enter a image to identify, it will make a judgement on small feature values such as whether the image has any circle, if so how many circles, and whether the circles are in complete form. Later, it will make a judgement on bigger features and finally, on the overall figure of the image.
Deep learning is made up of multi-layered neural network, so in each layer it makes a judgement on feature values.
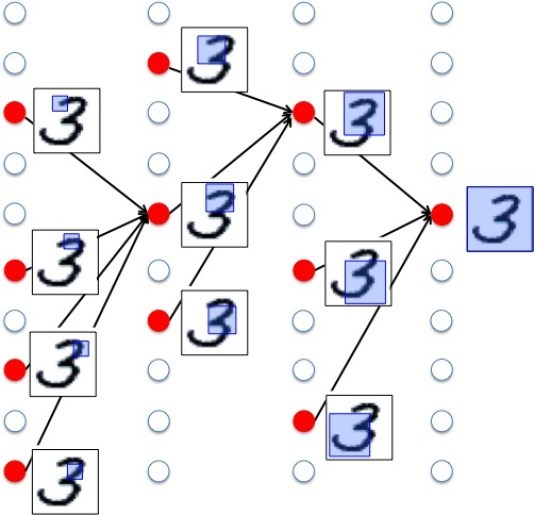
The important factor here is, what feature values it uses to make a judgement.
In deep learning, by reading some hundred thousands data sets of hand-written numbers for learning combined with correct answers, it will be able to extract feature values.
It can learn on its own what features to extract for learning.
The biggest advantage of deep learning is the ability to extract feature values automatically from tremendous amount of data.
When we look at the famous study of the Google successfully obtaining the concept of a cat.
In this study, they input ten million images from Youtube as data set for learning. As a result, it became capable of identifying cats.
An impressive part of the study is that, despite having not input any correct image of cats, it became capable of identify cats.
By inputting tons of images, it learned to identify “cats” on its own.
The reason behind choosing “cats” as the focus of the study is because the most posted type of videos on YouTube was those of cats, and if it became capable identifying cats after the study, it would learn to identify human faces as well.
When we look at the feature values extracted by the system, we notice that the parts to be identified in the first step were the angle of lines, circles and squares – those in details. Then eventually the focus moved to the shape of eyes and ears, and in the final step, it identified face – overall figure of the image.
This is very similar to how humans identify objects.
It is very convincing how the system obtained the concept by self-learning.
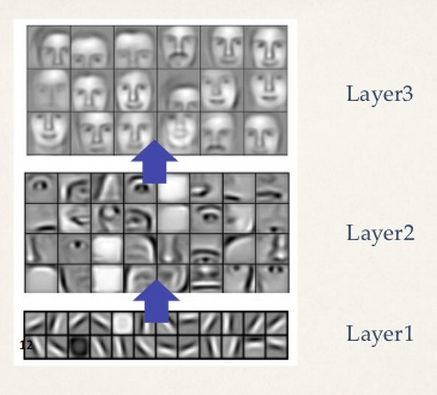
From the findings of the Google study, it was revealed that if we let deep learning learn from tons of data, it will become capable of identifying objects like we humans do.
So that’s how people started to believe that if we input tons of document data into deep learning, it will obtain concepts on its own, and in the near future it will develop a cognitive mind like human’s.
However, this did not happen in reality.
Then, why couldn’t we develop the same kind of mind as human’s by letting deep learning study tons of data?
Let us look from another perspective.
The original data from YouTube would have back figures of cats, so it should have extracted the features of a back of a cat.
Hence, it obtained two concepts – a cat from the front and a cat from the back.
Then, does the system identify that they are in fact the same cat – just seen from different angles?
In fact, it does not identify that way.
Because the images given to the system were only two-dimensional.
To be able to make a judgement whether the image match feature values, it rotates it, moves it parallel and zooms in and out – however, this is all done on the basis of two-dimensional images.
It can be said that the system does not comprehend a concept as three-dimension.
It does not comprehend that three-dimensional objects look different when seen from a different angle.
If objects were hand-written or originally two-dimensional, a problem like this would not happen.
Then, will deep learning able to identify from a two-dimensional picture the original object in three-dimensional form?
In other words, if an object expressed in the form of three-dimension, a high dimension, are expressed into lower dimension, will deep learning be able to identify its true form, in three-dimension?
Is this the limit of deep learning?
In conclusion, it is not impossible.
(Although it is yet to be actualized. )
What will make it possible then? For example, let me prepare feature values as three-dimensional models.
Then, when making a judgement on the match between the image to be identified and feature values, it will rotate three-dimensional model’s feature values in the three-dimensional space or it will them so to determine the match.
Then, from a two-dimensional picture, we will be able to identify its authentic form, in three-dimensional form.
From this, the reason why deep learning cannot identify three-dimensional objects does not fall into the limit of deep learning. Rather, it is the limit of the method of image recognition, which can only control images on the two-dimensional plane.
If the true state of an object to identify is three-dimensional, and it can control in three-dimension, it should be able to identify three-dimensional objects, too.
This is the system that has fully comprehended the three-dimensional world.
This system should also be able to identify a cat from the front and the one from the back as the same cat.
From this point, we will go back to the topic of natural language processing.
In image analysis, it analyzes the source of a image, pixels. In natural language processing, after inputted document data, it divides by words, measure frequency of appearance of words, and analyzes grammatical relationship of words.
Words are embodiments of what we picture inside the head.
What expressed in words are part of the image inside the head.
Hence, the image inside the head represents the high-dimensional world, and the linguistical world is what has been put into the low-dimensional world.
Even if we controlled a two-dimensional partial picture of the three-dimensional world on the two-dimensional plane, we would not be able to identify actual three-dimensional objects.
Like this, even if we controlled words dimensionally by analyzing the frequency of appearance or grammatical relationship of low dimensional words, we would not be able to replicate the actual image inside the head.
Let alone by inputting a tremendous amount of document data into AI , have them learn by deep learning, and it would have the same mind as humans.
Just as identifying three-dimensional objects items necessitates three-dimensional models, understanding human mind necessitates the model of human mind.
The model of human mind is a model which can replicate what we picture inside the head.
Then, what sort of function does the model of human mind have?
This is the world we humans picture inside the head, it would be able to identify three-dimensional space.
It would also be able to identify invisible time.
Furthermore, it would be able to understand emotions such as happiness and anger.
This is the model of human mind.
Next, we will be looking at the most crucial emotions.
The emotion of “happiness” comes when you obtain something “pleasure”.
The emotion of “anger” comes when you obtain something “displeasure” from the other person and the emotion is towards them.
In order to identify emotions, it needs to go through a procedure where it matches who did what impact (pleasure or displeasure) to whom.
The capability to control these indicates that it understands the model of human mind.
This is how it can identify whether the other person is happy or upset in a conversation.
If calculating the frequency of certain words is managed by the lower dimension, in the linguistical world, then judging who are the characters and who did what impact is managed by the higher dimension of the model of human mind.
You can’t make AI to comprehend human words by controlling the dimension of language.
What needs to be done at the foremost importance is to create the model of human mind.
Nonetheless, the current hype around AI only concentrates on deep learning.
ROBOmind-Project is one of the few projects that attempt to create the model of human mind.


ロボマインド・プロジェクトの最新情報はYouTubeで!



