



【マインド・エンジン】絶対不可能といわれていたコンピュータによる言葉の意味理解。ついに成功したので公開します。
AIブームの中、ディープラーニングに任せれば、何でも人間よりうまく処理できると思われていますが、ディープラーニングでは、絶対、人間を超えられないものがあります。
それは、普段、我々が使っている言葉の理解(自然言語処理)です。
それでは、どこに、ディープラーニングの限界があるのか、どうすればAIが言葉を理解できるようになるのかについて説明しましょう。
まずは、手書き数字認識を参考に、ディープラーニングをおさらいします。
数字は、全体的に丸なのか直線なのか、部分的に丸があるのか、いくつ丸があるのか、完全な丸なのか、一部がかけている丸なのかといった特徴があります。
数字認識するとき、この特徴量を使って判断するわけです。
認識する画像を入力すると、まず、小さい部分に分けて、丸があるか、あるなら何個か、完全な丸かといった小さい部分の特徴量で判断し、次により大きい部分、最後に全体像で判断します。
ディープラーニングは、多段階のニューラルネットワークで構成され、各階層で、これらの特徴量を判別します。
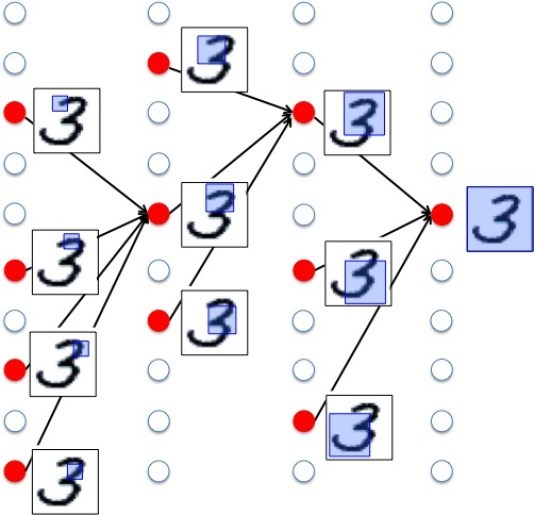
ここで重要なのが、どのような特徴量を使って判断するかです。
ディープラーニングでは、数10万枚の手書き数字の学習用データセットと、正解の数字の組み合わせを読み込ませることで、自分で特徴量を抽出することができます。
どのような特徴を抽出したらいいかを、自分で学習することができるのです。
大量のデータから自動で特徴量を抽出できる、これが、ディープラーニングの最大のメリットと言えます。
次に、猫の概念を獲得したとされるグーグルの有名な研究を見てみましょう。
この研究では、1000万枚のYouTubeのサムネイル画像を学習用データセットとして学習させた結果、猫を認識できるようになったというものです。
この研究の凄いところは、正解として猫の画像を与えていないのに、猫を認識できるようになったということです。
大量の画像を読み込ませただけで、そこから勝手に「猫」を認識できるようになったわけです。
なぜ猫だったかというと、YouTubeに投稿される動画で一番多いのが猫だったから、猫を一番よく認識できるようになったということで、猫以外にも、人の顔なども認識できるようになっていました。
このシステムが抽出した特徴量を見てみると、最初の段階で認識するのは、線の傾きや、丸や四角などの細かい部分で、それが次第に、目や耳の形となり、最後の段階では、顔などの全体を認識しているのが確認できます。
これは、人間がものを認識するときとそっくりです。
学習によってシステムが概念を獲得したといわれるのも頷けます。
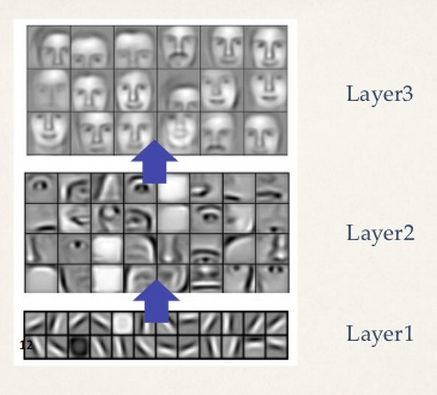
このグーグルの研究から、大量のデータを用意して、ディープラーニングで学習させれば、人間と同じようにものを認識できることがわかりました。
このことから、ディープラーニングに大量の文書データを読み込ませれば、自動であらゆる概念を獲得し、いずれ、人間と同じように認識する心が生まれるのではと思われるようになったのです。
ところが、実際は、そうはなっていません。
それでは、なぜ、大量のデータをディープラーニングで学習させただけで、人と同じ心は生まれないのでしょう?
別の観点から見てみましょう。
元となったYouTubeのデータには、猫の後ろ姿も写っていたはずなので、おそらく、猫の後ろ姿の特徴も抽出していると思われます。
つまり、正面から見た猫と、背面から見た猫の二つの概念を獲得したことになります。
それではこのシステムは、正面から見た猫と、背面から見た猫を、見る方向が違うだけで、同じ猫だと認識しているでしょうか?
結論から言うと、認識していません。
なぜなら、このシステムに与えられた画像は、2次元画像だけだからです。
特徴量に一致するかどうか判断するのに、画像を回転したり、平行移動したり、拡大縮小しますが、これは、すべて、2次元が前提となっています。
つまり、システムは、3次元というものを理解していないと言えます。
3次元の物体は、見る方向が変わると形が変わるといったことを理解していないわけです。
対象が手書き文字など、元々2次元のデータ認識なら、このような問題は起こりません。
それでは、2次元の写真データから、本来の姿である3次元物体をディープラーニングで認識することは可能でしょうか?
言い換えると、3次元という高次元の形で表現された物体が、2次元という、低次元の形で表現されていた場合、本来の3次元の姿をディープラーニングで認識できるのでしょうか?
これがディープラーニングの限界なのでしょうか?
結論からいうと、これは、不可能ではありません。
(まだ実現されていませんが)
どうすれば可能になるかといえば、たとえば、特徴量を3次元モデルとして用意しておきます。
そして、認識する写真と特徴量の一致を判断するとき、3次元モデルの特徴量を3次元空間内で回転させたり、移動させたりして2次元画像と一致するか判断するのです。
そうすれば、2次元の写真からでも、本来の姿の3次元で認識することは可能となるでしょう。
このことから、ディープラーニングで3次元物体を認識できないのは、ディープラーニングの限界というより、画像を2次元平面内でしか操作しない画像認識の手法から来る限界と言えます。
認識するものの本来の姿が3次元であるなら、3次元で操作することができるなら、3次元の物体も認識することができるはずです。
これが、3次元世界を理解したシステムと言えます。
そのシステムは、正面から見た猫と、背面から見た猫を、同じ猫と認識することもできるはずです。
さて、ここから自然言語処理の話に戻ります。
画像解析では、画像の元となる画素を解析するように、自然言語処理では、文書データが与えられると、単語に区切り、単語の出現頻度を測定したり、単語の係り受け関係を解析したりします。
言葉というものは、人が頭の中に思い描いたイメージを表現したものです。
言葉で表現されたものは、頭の中に思い描いたイメージの一側面です。
つまり、頭の中に描いたイメージが高次元の世界で、それを低次元の世界に落とし込んだのが言語の世界と言えます。
3次元世界の一側面を写した2次元の写真を、2次元平面内だけで操作しても、実体である3次元を認識することができません。
それと同じように、低次元で表現された言葉を、単語の出現頻度や係り受け関係を解析するといった、言葉の次元の操作だけしても、本来の姿である頭の中のイメージを再現することはできません。
ましてや、大量の文書データを読み込ませただけで、ディープラーニングが自動で学習して、人間と同じ心が生まれるといったことは到底あり得ません。
3次元の物体を認識するのに3次元モデルが必要なように、人の心を理解するには、人の心のモデルが必要なのです。
人の心のモデルとは、人が頭の中のイメージを、そのままの姿で再現できるモデルとなります。
それでは、心のモデルとは、具体的には、どのような機能をもっているでしょう?
人が頭の中で思い浮かべる世界なので、3次元空間を認識できるでしょう。
さらに、目に見えない時間といったものも認識できるでしょう。
そして、喜びや怒りといった感情というものも理解できるでしょう。
これが、心のモデルなのです。
次は、この中で、最も重要な感情について考えてみましょう。
「喜び」の感情とは、自分が「快」となるものを得たときに生じます。
「怒り」の感情とは、自分が「不快」となるものを相手から得たとき、その相手に向けられる感情です。
感情を認識するためには、誰が、誰に対して、快、不快の影響を与えたかといったことを当てはめる操作が必要になるわけです。
こういった操作ができることが、心のモデルを理解しているといえるのです。
これができてはじめて、会話をするとき、話し相手が喜んでいるのか、怒っているのかといったことを認識することができるのです。
単語の出現頻度を計算したりするのが、言語世界である低次元の操作とすれば、登場人物は誰で、誰が誰にどんな影響を与えたかといったことを判別するのが心のモデルの高次元の操作といえます。
AIが、人間の言葉を理解できるようになるためには、言葉の次元の操作をいくらやっても無駄なのです。
最初にやるべきことは、心のモデルを作ることなのです。
しかしながら、現在のAIブームは、ディープラーニング一辺倒です。
ロボマインド・プロジェクトは、心のモデルを作ろうとする数少ないプロジェクトです。


ロボマインド・プロジェクトの最新情報はYouTubeで!







