 東ロボくんは、なぜ失敗したのか 「AI vs. 教科書が読めない子どもたち」批評1
東ロボくんは、なぜ失敗したのか 「AI vs. 教科書が読めない子どもたち」批評1 文章を読めればAIに仕事を奪われない? 「AI vs. 教科書が読めない子どもたち」批評2
文章を読めればAIに仕事を奪われない? 「AI vs. 教科書が読めない子どもたち」批評2 コンピュータで文の意味を理解しよう 「AI vs. 教科書が読めない子どもたち」批評4
コンピュータで文の意味を理解しよう 「AI vs. 教科書が読めない子どもたち」批評4 「太郎は花子が好きだ」をコンピュータに意味理解させました 「AI vs. 教科書が読めない子どもたち」批評5
「太郎は花子が好きだ」をコンピュータに意味理解させました 「AI vs. 教科書が読めない子どもたち」批評5 「AI vs. 教科書が読めない子どもたち」批評の感想をいただきました
「AI vs. 教科書が読めない子どもたち」批評の感想をいただきました
【マインド・エンジン】絶対不可能といわれていたコンピュータによる言葉の意味理解。ついに成功したので公開します。

自然言語処理では、今まで、どのような処理が行われてきたのか。
「AI vs. 教科書が読めない子どもたち」で、新井紀子教授は、以下のようにまとめています。
AIが文章を論理的に読めるようになるとしたら、まずは文がどこで区切られるか、つまり文節が理解できなければなりません。
それができたら、「何がどうした」という主語と述語の関係や修飾語と被修飾語の関係を理解しないければなりません。
これを「係り受け解析」と言います。
また、文章には「それ」「これ」といった指示代名詞が頻繁に出てきますから、指示代名詞が何を指すかも理解できなければなりません。
それを「照応解決」と言います。(p186)
東ロボくんは、これらの処理を大学の入試問題に適用して、代名詞が何を指すかといった入試の問題が解けるようになったわけです。
それでは、係り受け解析や、照応解決ができたからといって、意味がわかったといえるでしょうか?
それだけでは、意味を理解したとは言えないでしょう。
それでは、そもそも、「意味を理解する」とは、いったいどういうことなのでしょう?
20年ほど前、僕が、物語の自動生成プログラムを作ろうと思い立ったとき、まさに、この問題に直面しました。
当時、すでに、係り受け解析や照応解決などの自然言語処理の技術は完成していましたが、コンピュータで意味理解する方法に関しては、誰も実現していませんでした。
僕も、当初は、どこかの大学で自然言語処理を学ぼうと考えていたのですが、いくら探しても、僕がやりたいことを教えてくれる先生や大学がみつかりませんでした。
学会にも属して、過去の論文から最新の論文まで広く目を通しましたが、コンピュータでの意味理解の手法は見つかりませんでした。
その頃になって、ようやく、僕のやろうとしていることは、今まで誰もやったことのないことでなので、過去の論文などいくら探しても見つからないということに気づきました。
過去の技術の延長線上にあるのであれば、過去の論文がヒントになるかもしれません。
もし、それで実現できるなら、自然言語処理の50年の歴史の中で、既に誰かが実現しているはずです。
僕がやろうとしていることは、今までの自然言語処理の延長線上には存在しないようです。
そうなると、論文を探すのでなく、自分の頭で考えだすしかありません。
根本的に新しい方法を見つけ出さないといけないようです。
前回の話で言えば、読解能力値でなく、クリエイティブな能力が必要なところと言えます。
僕がまず取り組んだのは、そもそも、「コンピュータで意味を理解する」とはどういうことかについてでした。
何が実現できれば、コンピュータで意味を理解したといえるのか、そのことについて考えました。
そこで得られた回答の一つは、「意味理解とは情報処理である」というアイデアです。
例をあげましょう。
1+1=2
という計算があるとします。
左辺の「1+1」を計算した結果が「2」となります。
これを、「1+1」の意味は「2」と考えるわけです。
これを別の見方をすれば、「1+1」という情報量が「2」という情報量に減少したといえます。
つまり、「意味理解とは、元あった情報量を減少させる情報処理」と考えることができます。
つぎは、将棋を例に挙げてみます。
将棋は、互いに駒を進め、最終的にどちらかが相手の王将を取った段階でゲームが終了します。
勝敗が決まると、それ以上駒を動かすことはなく、盤面の情報量は最小となります。
ゲーム開始段階では、あらゆる駒を動かす可能性があり、盤面の情報量は最大といえます。
将棋の意味とは、敵の王将を取るために駒を進めることといえます。
もし、自分が不利となるように駒を進めたとしたら、なぜその位置に駒を進めたのか意味がわかりません。
後々、その一手が決め手となって勝ったとき、その一手の意味がわかります。
このことから、「意味理解」のもう一つの側面が見えてきました。
それは、「意味を理解するとは、相手の行動が予測できること」といえます。
ルールを共有し、相手がなぜそう動いたか、次はこう動くだろうと予測できること。
これは、相手の意図がわかるとも言えます。
これが、行動予測からみた意味理解です。
それでは、これらの意味理解の定義を、従来の自然言語処理に当てはめてみましょう。
「文」を「文節」に切り分ける処理、文節の「係り受け解析」、指示代名詞の「照応解決」、どの処理をしても、元の情報量が減少することはありません。
むしろ、情報量は増加します。
つまり、これらの解析処理は、意味理解をしているとは言えません。
また、会話において、係り受け解析や、照応解決が完璧にできたとしても、相手が次のどう言うか、予測することはできません。
行動予測からみた意味理解もできていないと言えます。
それでは、つぎは、文の意味理解について考えてみましょう。
新井教授は、文の意味理解について、以下のように述べています。
AI(コンピューター)が計算機であるということは、AIには計算できないこと、基本的には、足し算と掛け算の式に翻訳できないことは処理できないことを意味します。(p108)
このことを理由に、言葉を計算する方法が存在しないので、意味理解は不可能だと結論付けています。
実際、コンピュータ(CPU)の中には、足し算回路や、掛け算回路が存在し、コンピュータプログラムは、最終的にはこれらの演算回路で実行されます。
意味を理解するとは、情報量を減少させる処理だと説明しました。
コンピュータでは、演算回路を使って計算することが意味理解になります。
コンピュータの演算回路に相当するものが人間の脳の中にあるとすれば、その回路を使って処理することこそ、意味理解だといえます。
それでは、脳の中には、どのような回路があるのでしょう?
そのことについて、以前「ウェイソンの4枚のカード問題」として記事を書きましたので、詳しくはそちらの記事を読んでいただきたいのですが、ここでは簡単に紹介します。
クイズを2題出します。
・クイズ1
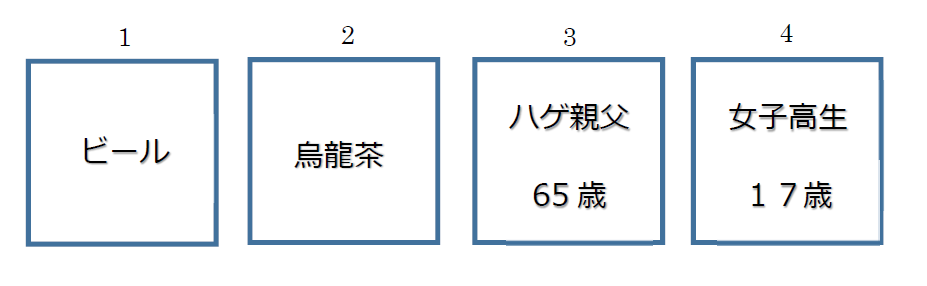 居酒屋のカウンターで4人が飲んでいます。1番、2番は席を外して飲み物だけが置いてあります。
居酒屋のカウンターで4人が飲んでいます。1番、2番は席を外して飲み物だけが置いてあります。
1番は、ビール、2番は烏龍茶です。
3番はハゲ親父(65歳)で、4番は女子高生(17歳)が座っていますが、何を飲んでいるのかはわかりません。
さて、この中で、何番と何番を調べれば、誰が未成年で飲酒しているか確認できるでしょう?
簡単な問題ですよね。
1番のビールを飲んでるのが何歳かと、4番の女子高生がアルコールを飲んでるかを調べればいいわけです。
・クイズ2
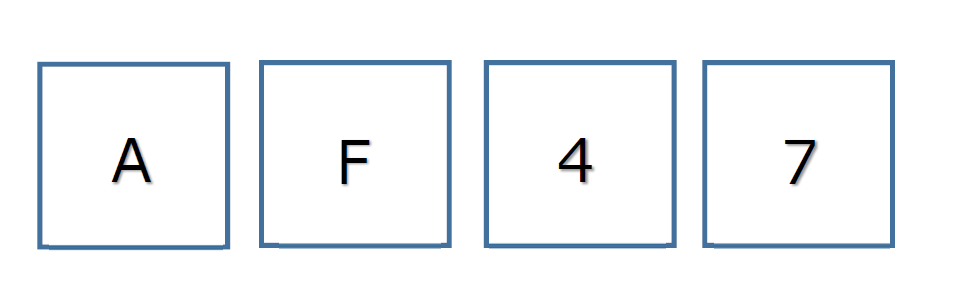 ここに、4枚のカードがあります。
ここに、4枚のカードがあります。
それぞれ、片面にはアルファベット、もう片面には数字が書いてあります。
「片面のアルファベットが母音なら、その裏面は偶数でなければならない」
というルールが成立しているかを調べるには、どのカードとどのカードをひっくり返して確認すればいいでしょう?
急に、難しくなりましたね。
でも、この2題の問題は、数学的には全く同じ問題なのです。
なぜ、カードの問題は難しく感じたのでしょう?
僕は、それは、脳の中にある演算回路を使えたか、使えなかったかの違いだと考えました。
人間は、社会的な生物なので、ルールを破ってズルをしている人がいないかを検出する機能があると考えました。
その機能が、脳の中の回路というわけです。
このズル検出回路を使えば、一瞬で、誰がズルしているか見極めることができるのです。
考えなくとも、直感でわかります。
この回路を適用できるのは、社会的ルールの場合だけなので、数学的に同じだとしても、社会的ルールでない4枚のカード問題には適用できません。
そうなると、頭の中であれこれ考えないといけないので、すぐに答えられず難しく感じるのです。
この回路を使えば、居酒屋の状況において、誰が未成年飲酒をしているかの結果をすぐに得ることができます。
計算によって、情報量を減少させているのです。
情報処理による意味理解ができています。
また、誰に何を聞けば、未成年飲酒か確認できるかがわかります。どう行動するか予測ができるわけです。
つまり、行動予測からみた意味理解もできます。
情報処理と行動予測の二つの意味理解ができているといえます。
これで、ようやく文の意味理解の準備が整いました。
次回は、以上を踏まえて、文の意味理解の方法について説明します。
YouTubeも併せてご覧ください。



ロボマインド・プロジェクトの最新情報はYouTubeで!







