 そもそも意識って何?人工知能で人工意識は作れるの?
そもそも意識って何?人工知能で人工意識は作れるの? チューリングテスト
チューリングテスト 感情とは 認知パターンって何?
感情とは 認知パターンって何?
【マインド・エンジン】絶対不可能といわれていたコンピュータによる言葉の意味理解。ついに成功したので公開します。
さて、前回「そもそも意識ってなに?」で説明したように、人間は、意識があるから、見ているという感覚を持っています。
意識で世界を見ているわけです。
視覚の腹側視覚路が損傷すると、「見ている」という感覚自体が失われるという話をしましたよね。
僕たちが、普通に、周りの光景を見ているこの「見ている」という感覚は、意識があって初めて生まれる感覚なのです。
人間以外の動物は、同じように見ているわけではありません。
人間と同じ心を持つロボットを作るには、この意識を作らないといけません。
では、どうやって意識を作ったらいいでしょう?
まずは、意識が無意識に比べて、いかに優位かについて説明します。
意識がない場合
意識がない場合とは、前回のカエルやライントレーサー、自転車を運転する場合です。
目などの感覚器から入力されるデータを常時監視し、決められたパターンのデータが来れば、それに応じた行動を行います。
入力から出力まで止まることのない一連の流れとなっていて、決められた動作が自動で行われるだけです。
たとえばライントレーサーの場合だと、4つの点だけで、全てを判断しています。
4つのセンサーが一列に並び、それぞれが白か黒かを判断し、それだけの情報でラインからどれだけずれてるかを決めているわけです。
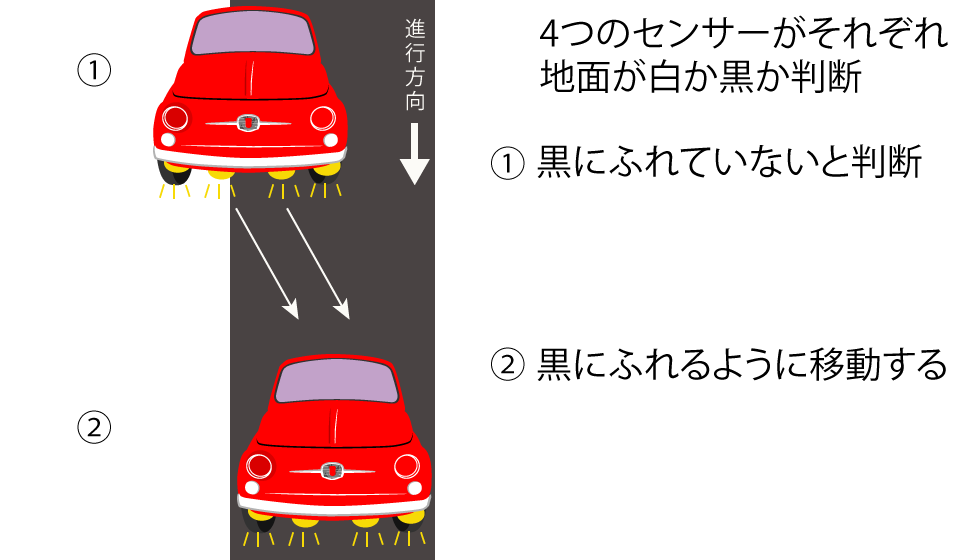
この世界の状況を4つの白黒だけで判断しているわけですから、かなり簡略化した世界となります。
ライントレーサーにとって、世界は4つの白黒の点なのです。
カエルの場合も同じです。
目の前で何かがチョコチョコ動くかどうかで虫を判別しているので、チョコチョコ動くかどうかを検出しているだけです。
この無意識モデルの問題点は、決められたパターンにしか対応できないということです。
ライントレーサーだと、ゴミが落ちているだけで、ラインを読み間違えてコースからすぐに外れてしまいます。
カエルの場合なら、虫なら何でも食べてしまうので、毒虫も食べてしまい、死んでしまうこともあります。
この問題は、進化によって解決することは可能です。
たとえば、黄色い虫が毒虫だったとします。
黄色い虫を食べない遺伝子を持ったカエルは生き残りますので、その子孫が繁栄していきます。
このようにして、環境の変化に対応した生物が生き残っていくわけです。
ただし、環境に適応できるまでに何万年もかかったりします。
当然、環境に適応できない個体は死んでしまいます。
我々の感覚から言えば、いくら子孫が繁栄しても、自分が死んでしまえば意味ないですよね。
その自分自身で環境に対応できるようにならないと意味がありません。
そこで出てきたのが意識です。
意識がある場合
意識は、「このリンゴをいつ食べようかなぁ」などと、試行錯誤できます。
「この黄色い虫は食べても大丈夫かなぁ。この前、黄色い虫を食べて気分が悪くなったから食べないでおこう」
とか考えることができるわけです。
つまり、考えて、行動パターンを後から変更することができるのです。
何万年もかけて進化しなくても、学習によって、自分自身で環境に適応することができるようになるのです。
このように意識は無意識に比べてかなり優れていますが、意識のモデルはどのように構築すればいいのでしょうか。
カエルを例に考えてみます。
単に、チョコチョコした動きだけで虫と判断している場合、色も判断材料に入れるという対応ができません。
色が重要なのか、形が重要なのか、なにが重要なのか予め分かるわけではありません。
チョコチョコした動きを検出していただけではダメなのです。

どんな状況にでも対応できるようになるには、考えられる、あらゆる状況に対応できるようになっていないといけないのです。
単純なパターンのみ認識するのでなく、まわりの状況そのものを認識できないといけないのです。
つまり、まわりの世界をありのままに認識すること。
これが意識の重要なポイントなのです。
世界をありのままに認識するにはどうすればいいのでしょう?
単純にCCDカメラで周囲を撮影し、それを投影すればいいのでしょうか?
試しに、眼球で捉えた映像を脳内のスクリーンに投影してみましょう。
この場合、投影した画像を誰が認識するのでしょう?
その画像を認識するには、また、それを認識する人が必要となります。
頭の中に小人がいるイメージです。
そうなると、今度は、その小人が認識するには、小人の中に、さらに小人が必要となります。
これを頭の中のホムンクルスと言って、人工知能のパラドックスとして有名な話です。
ホムンクルスを使う限り、何も解決できません。
それでは、ホムンクルスを使わずに世界を認識するにはどうすればいいでしょう。
まずは、我々がどうやって世界を感じているのかを、脳での視覚処理を元に考察してみます。
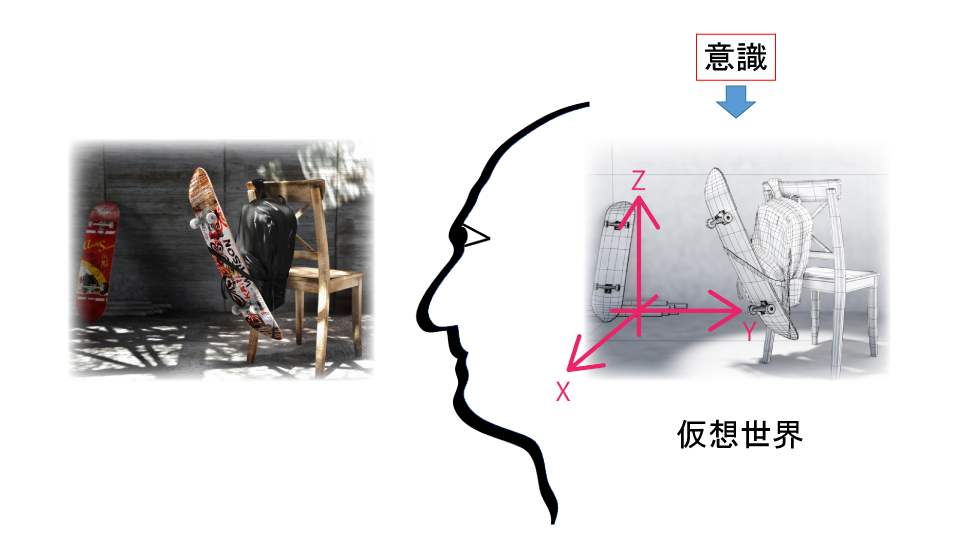
我々は二つの眼で見ていますが、世界が二重に見えているわけではありません。
このことからも、眼球で捉えた映像を単に脳内のスクリーンに投影しているだけでないことが分かります。
眼が二つある理由は、視差効果を使って物を立体的に把握するためです。
そうやって、世界を奥行きのある3次元空間として認識しています。
脳内では、二つの眼で捉えた二種類の画像を統合し、意識が世界を立体的に把握できるように処理しているのです。
視覚だけでなく、聴覚や臭覚からの情報も統合され、ありのままの世界を認識できるように、世界を脳内で再構築しているのです。
我々は、眼や耳を通して現実の世界を感じていると思っていますが、実は、我々の意識が直接感じ取っているのは、脳が作り上げた仮想世界なのです。

我々は、3次元空間の中で生活していると当たり前のように感じています。
ところが、これは、意識があって初めて感じられることなのです。
ライントレーサーについて考えてみましょう。
ライントレーサーにとって、世界は4つのセンサーのオン/オフだけです。
ライントレーサーが感じるのは、4つのセンサーのうち、どのセンサーがオンで、どのセンサーがオフかだけです。
世界とは「白い紙に黒いラインが引かれたものだ」という世界観すら持っていません。
なぜなら、センサーのオン/オフから、自分はどんな世界を走っているのか想像する能力がないからです。
4つのセンサーでなく、1000万画素のCCDカメラを搭載したとしても同じです。
センサーが高性能になったからといって、世界は3次元空間からなり、自分はその世界の地面に描かれたラインに沿って走っていると理解できるようになるわけではありません。
このことは、カエルでも同じです。
その生物(ロボット)にとっての世界は、その生物が、入力されたデータをどのように処理しているかに依存しているのです。
目で見た世界を3次元空間として処理して初めて、世界は3次元空間として立ち現れてくるのです。
我々が見ているのは、脳が生成した仮想世界。
つまり、幻想なのです。
したがって、現実の世界が、我々が見て感じている世界と同じだと断言することはできません。
それは、ライントレーサーが、世界は4つのセンサーのオン/オフだと断言するのと同じことです。
ただ、進化の過程で、我々は、世界をありのままに認識しようと決めたことは間違いありません。
そうであるなら、おそらく、世界は我々が見ているとおりの世界だろうとはいえると思います。
重要なのは、我々が見ている世界が、ありのままの現実の世界であるかどうかではありません。
ロボマインド・プロジェクトが目指すのは、人と自然なコミュニケーションができるAIです。
重要なのは、AIが感じている世界と人が感じている世界が同じかどうかです。
同じ世界を感じていればコミュニケーションが可能となります。
これは、「チューリング・テスト」で説明したことですが、人とコミュニケーションがとれるためには、人と同じ世界を共有する必要があるからです。
主観と客観
我々の意識が世界を認識することで、もう一つ、重要なポイントが見えてきます。
意識は、脳内で再構築された世界を見ています。
世界を見るという行為、これは、世界とは別に、世界を見ている自分がいるわけです。
世界と分離された自分がいるのです。
これが主体です。
世界を見るという行為を通して、自分という主体が生じるのです。

無意識モデルの場合、入力から出力までの一連の流れの中に自分が含まれます。
この場合、自分は世界の一部です。
自分が世界に含まれ、世界と一体となっていれば、世界に対峙する主体は生じません。
意識は、自分を含む世界を外から見る自分を感じます。
これは、自分を見る他人の視点にもなり得ます。
ここから、客観的に自分を見る視点が獲得できたのです。
客観的に自分を見ることができるようになると、他人も、自分と同じように感じていると想像できるようになります。
他人の気持ち、相手の心の痛みが分かるようになるのです。
「認知パターン」で説明したように、自分の快/不快だけでなく、相手の快/不快が理解できるようになって、初めて、善悪や倫理観といった人間のみ持ちうる認知パターンが獲得できるようになったのです。
頭の中に世界を再構築すること。
再構築した世界を見る意識。
これこそ、心の本質であり、人と自然な会話ができるAIに絶対必要な機能なのです。


ロボマインド・プロジェクトの最新情報はYouTubeで!








[…] 主観と客観 […]
世界を脳内で再構築しているということは、環境のモデル(信念)を持っているということでしょうか?
その場合、新たな情報に基づくメンテナンス(信念の見直し)を 何処まで行えばよいか という 哲学者J.A.フォーダーのフレーム問題が生じると思います。
質問、ありがとうございます。
環境のモデルにはなると思いますが、信念に当たるかどうかはわかりません。
哲学者J.A.フォーダーのフレーム問題というのが、正確にはわかりかねますが、「フレーム問題」というからには、特定の条件に当てはまる解を探索する際、無限に探索してシステムがフリーズする問題が生じる現象を指すものとおもわれます。その場合、「フレーム問題は解決済み」で説明しましたように、特に問題にならないと思います。
無限探索に陥った場合の解決方法として、探索する範囲を絞ったり、探索する回数で制限をかけたりすれば、少なくともフリーズするといったことはなくなります。
個人的に思うのは、哲学者って、ホント、フレーム問題が好きですよね。
たぶん、「無限」って言葉にロマンを感じているのでしょう。
プログラマーの立場から言えば、無限探索に陥るバグなんて、しょっちゅう起こるリアルな問題なので、これで騒ぐ人をみると、「何言ってるの?」と思いますが。
デバッグしてて、stack overflow なんてエラーが出たら、アチャーと凹みはしますが、「これがAI最大の難問だ!」などと大げさに悲観する人はいないです。
自分でプログラムを書いたことなくて、頭の中で妄想するだけの哲学者にとって、フレーム問題を見つけたら、天下を取ったような気になるのでしょう。
フレーム問題について
フレーム問題のページについてですが、問題を単純化しすぎている気がします。真にAIを試すなら、爆弾の効果が及ぶ範囲、起爆装置のセンサ(自分が認識された爆発するかも知れないし、持ち上げたら爆発するかも知れない)、いくらでも思いつきます。その上、自己保存を優先するべきか、洞窟の中のバッテリーは本当に必要か(自分が破壊される危険を冒すほど価値のあるものか?)、など人間がこの状況のロボットを自分に置き換えたとしても悩むことはたくさんあるように思います。これらの問題は無限ではないにしても、多くの可能性が想定されますし、それを確実に証明できない場合もあります。その場合、AIはどう判断するのでしょうか? 優先順位(範囲限定)を全てあらかじめプログラムしきれるのでしょうか。
ただ、検索の回数を限定するという方法はある程度納得のいく回答かも知れません(あくまで、人に似せた不完全な存在を作るならば、ですが)。
哲学者と無限について
無限にロマンを感じる哲学者、というのは正直、偏見に過ぎます。現代の哲学者はなかなか残念なほどにリアリストが多いので、あなたのイメージはステレオタイプ過ぎるかと。
それに意識しているかどうかが違うだけで、人は多少なり無限とかに憧れていると思いますよ。それが、現状の課題に対して優先されないが故に、無限への憧れは無視されているだけで、無限について考えればロマンは感じられると思います。
ダニエル・デネットは仮想世界理論でしたっけ、に近いことを述べていますよ。
哲学者フォーダーのフレーム問題は軽く調べただけではよくわからなかったので、推測ですが、おそらくはある情報を得て、そこからAIが何かを判断しようとする際に、継続的に新たな情報(おそらくは特に別の観点から得られた情報:センサの位置や種類の違い?)がAIに与えられるとAIは先に与えられた情報が後から与えられた情報に反する場合どちらを信用して良いか判断できなくなるという性質のものだと思います。特に、ネットなどから得られた内容にのみ基づいて考える場合などや、答えが確定しきれない問題に、取り組むと悩み続けてしまう、というものだとお思います。(問題に対する答えの階層化と条件付けである程度まではなんとかなるのかも知れませんが、プログラムする人間があらかじめ事態の想定を行わなけらばいけない気がしますし)
フレーム問題が真に指摘しているのは、まともに取り組めば人間も無限に悩み続けてしまうような問題にどう対応するのかなのではないですか。
フレーム問題の解決は「解決すること」ではなく、「いかに解決できない問題に対応するか」なのだと思います。
もし、真に人間的なAIの開発を目指すなら(人間にできないことを可能にするAIではなく)人間が普段から懐疑主義に陥らないシステムをAIに応用するべきなのでしょう。(言うまでもないでしょうが)
中畑様
コメントありがとうございます。
僕も、フレーム問題を完全に解決できたとは思っていません。
僕が解決済みと言っているのは、爆弾を乗せたバッテリのような、人間なら何の問題もなく解決できる問題なら、AIロボットにも解決できるということです。
人間が完全にフレーム問題を解決していないという意味なら、人に似せた不完全なAIロボットという表現は正しいです。
ダニエル・デネットは、バッテリ問題すら解決できないから、AIロボットを現実世界に投入できないと言いたいようですが、そんなことはないと反論するのが僕の書いた記事の目的です。
無限に存在する問題を全て解決することが可能だとは、さすがに思ってもいませんし、それを解決できないと現実世界で役に立たないとも思っていないもので。
「哲学者と無限」で、中畑さんが何がいいたいのか、ちょっと意図がわかりませんでした。
僕は「哲学者と無限」について言及した記憶もないですし、あまり興味もないのですが、これは、誰か他の人に向けてかかれた文章なのでしょうか?
「哲学者フォーダー」の「フレーム問題」は、僕もよく知らないですし、「フレーム問題」の記事を書いたときには、フォーダーのフレーム問題のことは、全く、念頭にありませんでした。
はい、僕もそう思います。
その解決方法の一つとして、人間が頭の中で行っているシミュレーションと同じようなことなら、現在のコンピュータ技術でも可能なので、その一例を示したわけです。
改めて「フレーム問題」で、僕が前提としている考えをここで書いておきます。
シンギュラリティや汎用人工知能を論じる際、目標とするのは人間と同等の知能です。
人間と同等の知能を持つAIができれば、あとは、マシンパワーを増強すれば、人間を遥かに超える知能を持つAIを作ることが可能です。
逆に、人間の知能に達しない限り、いくらマシンパワーを増強しても、人間を超えることはありません。
これが、人間と同等の知能を目指す一番の理由です。
「フレーム問題」においても重要なのも、この点と僕は考えます。
無限の可能性のある問題を全て解くことを目標とするのでなく、人間が無意識のうちに簡単に判断しているのと同じことがAIロボットにもできるようになれば、「フレーム問題」を完全に解けなくてもいいと思っています。
それでいいといより、それだけでも、ものすごく高い目標ですので。
それができれば、現実世界でAIロボットが一気に進出できます。
そころで、このコメント欄は、「主観と客観」の記事へのコメント欄です。
「フレーム問題」のコメントを書いてはいけないわけではないですが、少しでもいいので、「主観と客観」の記事にも触れていただければ、個人的に嬉しいもので。
なぜか、世間の人は「フレーム問題」に関心が高いようですが、正直、僕としては「フレーム問題」なんか、どうでもいいと思っていまして。
それより、「主観と客観」とか「意識の仮想世界仮説」の記事のほうが、面白い記事だと思うのですが、あまり反応がないので悲しいです。
久しぶりに反応があったと思ったら、中身は「フレーム問題」の話で、ちょっとがっかりしてしまいました。
ダニエル・デネットの文章は、回りくどくて、何が言いたいのかわかりにくいですよね。
もし、どの本のどこで仮想世界仮説に近いことを言っていたのかわかれば教えてください。
コメントの場所がずれていてすみません。このページの他の方のコメントとそれに対する応答についてのコメントでした。お返事への返信という形でもう少しこの話が続きますがご容赦ください。
ロボットの話で私が指摘したいのは、「爆弾」と関係のないことを疑って検索し続けると言う点ではなく、「爆弾」がバッテリーの上に乗っているということ、「爆弾」は持ち上げて避けてもなんら問題はないということ、というような情報が事前に与えられていなければどうなるだろうか、とう点です。(「爆弾という情報」が前提として与えられるのではなく、「爆弾らしき物体」がバッテリーの上に乗っているという情報しか与えられないケースの方が、より現実的な想定だと思うからです)
人間にしても、ロボットにしても、その「見た感じを経験と参照してみるとどうやら爆弾と思われる物体」がバッテリーの上に乗っている状態に、AIがどう対応するか、です。
哲学者の話については、他の方のコメントに対する応答で田方さんが述べられていたことです。哲学徒(と言ってもまだ一年ちょっとですが)としては癇に障る描かれ方がなされていたので、コメントしました。ああいった批判(というよりも非難)は実態を知らないにも関わらず、偏見を根拠に出された意見のように思えます。
ただ、実際、哲学者はそんなのばっかなイメージがあるので、仕方ない事かもしれませんが、別段、あのような描かれ方をされる必要性が、このブログにも、回答にもあったとは思えなかったので、余計な非難はされない方が良いと思い、指摘した次第です。
最後のフレーム問題の解決(解決しないことが解決?)については僕の理解がある程度は及んでいたようで何よりです。
ただ、僕が人工知能やチューリングテストについて思う単純な疑問なのですが、なぜ人間を目指すのかについてはやはり疑問が残ります。人間と同じ構造で、結果的に同じことをするAIを作ることはロマンがありますが、あくまでAIには人間とは違う目的を持たせるべきだと思います。(人間に決まった目的があるかはさておき、AIは少なくとも目的に応じて作られるべきでしょうから)
汎用型人工知能が何を目指すのかは知りませんが、それが人間でない限りは、実存的なあり方(目的が存在に先行しないこと)ではなく、なんらかの目的のためのものだと思います(多様な状況に対応可能な機械の製造)のように。では、フレーム問題についても人間と同じように無意識で判断しているように、AIが情報を切り捨てて良いのかは疑問が残ります。
むしろAIには人間が非合理的に切り捨ててしまっている情報や、人間の知覚能力ではそもそも認識不可能な情報を取り入れて必要な情報を取捨選択し、選択し判断することではないでしょうか。
もしかする、それは田方さんのおっしゃる次のステップなのかもしれませんが、その前段階が人間の完全な構造的模倣ではないように思えるのです。(あくまで参考ならいいのですが、人間らしいAIを作ろうとしすぎるあまり、人間の欠点を無理に模倣する必要はないと思います)
このあたりの考えは、チューリングテストのことで、AIが人間らしさを演出するためにわざと間違えたりする、という話をどこかで読んで思ったことです。
チューリングテストが人間らしさを目的としたAIの判断基準であることはわかっていますが、実際に与えた計算をたまに間違うことを、私たちはAIに求めているのかと、私は疑問に思ったのだと思います。
ダニエルデネットの仮想世界理論っぽい話はソースが残念なサイトですので、お恥ずかしながら文献を確信を持って伝えることはできません。もし今後、手に取ることがあればお伝えさせていただきます。
ページの趣旨から逸れた質問をしていることと、合わせて謝罪します。
中畑様
コメントありがとうございます。
この問題は、AIの学習によって解決できると思います。過去の事例から学習するのはAIの得意なところですから。
人間にも判断ができない状況は、AIが判断できなくても、今は問題ないと思います。まずは、人間にできることを目指すのが先決ですので。
哲学者への批判は、僕のどの文章のことを指しているのかわからないので、何とも言えないです。
ただ、僕がよく感じるのは、哲学の側からAIにアプローチするときは、もう少しAIの技術的な中身まで勉強してほしいということです。
哲学者の言うことは抽象論が多く、僕のようなプログラマーからみると、どうやって実現するの? 具体的に何を指しているの? といった疑問が多く出ることがありますので。
逆に、エンジニアは、技術にしか興味がない人が多いようで、僕の研究内容に対する批判が、枝葉の技術の批判だったりで、意識や心のモデルといった根本的な中身に対する批判はなかったりで、それはそれでさみしいのですが。
汎用人工知能を目指す目的は、人間と同じようなことができるAIができれば、ほとんどの仕事をAIにしてもらえるからって、単純な話ですよ。
実存的な目的で汎用人工知能を作ろうって思っている人は、まずいないと思いますよ(実存って言葉、久しぶりに聞きましたねぇ。サルトルとか、今でも読まれているのかなぁ)。
世間一般に、このあたりに誤解があるようです。
僕が、声を大にして言いたいのは、「今のAIなんて、本当に大したことないよ」ってことです。
チューリングテストに合格したAIがあるとかって話はよく聞きますが、今のAI技術で、本当に人と普通に会話できるAIなんかできるわけないです。
できてるのは、「おはよう」といわれたら「おはよう」と返すプログラムぐらいです。「おはよう」の意味も、挨拶の意味も理解して会話していません。
なので、少し話せば、トンチンカンな返答をしてきて、会話にならないです。例外なく全ての会話AIがこうです。
まず、そのことを理解しておいてください。
まぁ、技術者は大げさなことを言うのが好きなので、それを真に受けて批判すると、的外れな批判となります。
その程度のAIしかできてない現実をわきまえると、まずは、言葉の意味を理解して会話できるAIを作ろうとなりますよね。
「いつまで、そんな、おもちゃみたいなAIを作って遊んでるんだ」って批判をすべきなんです。
「わざと間違えて人間らしくした」とか、そんなのは、うまくできなかった技術者のただの言い訳です。
中身を見るまでもなく、僕なら、そう断言することができます。
それを見極めれる目を養ってください。
遅くなりましたが、このページの主体と客体についてのコメントをさせていただきます。
ホムンクルス問題について
まず、このパラドクスは視覚に重きを置きすぎた故の誤解として、半分は処理できると思います。田方さんがこのページ内で言及されているように、世界の中に私がいて、それを俯瞰すればホムンクルス問題は解決だというわけです。
しかし、本当にそうでしょうか。
私はこのホムンクルス問題がもう少し複雑な問題に思えます。というのも、世界(再構築されt仮想世界)の中にいる私は、俯瞰している視点とどのように同一化されるのか、という疑問が解消されていないからです。
より具体的に述べるなら、仮想世界内に周囲との関係から推測して構成される私は、もはや俯瞰している状態においては「客体化」されているのです。この時の「主体」は「俯瞰して世界を眺める私」であって、「仮想世界に構成された私」ではありません。
もちろん、どっちも私であることは(おそらく)自明ですが、この二つの「私」は同時には存在しません。
因みに、ホムンクルスのパラドクスの亜種(あるいは似たもの)として、ヘーゲルの考えたパラドクスがあります。それこそが今私が言っていることから始まる、「主体としての私は永遠に客体化されない」というパラドクスです。
これはあくまで私の表現ですが、主体としての私は、その私を思考の対象(つまり客体)にしようとした瞬間に、そこから脱皮して抜け出し、その抜け殻を眺める主体になってしまうのです。
これがホムンクルスのパラドクスのもう一つの側面ではないでしょうか。
単に2Dを3D化し、自分を世界の中の存在として3Dの中に構成するだけで、ホムンクルス問題が解決したとは思えません。
むしろホムンクルス問題が抱えていた二つの側面から、一面を剥ぎ取って、パラドクスを純化しているにすぎないように思えます(もし本当ならそれだけでも大変な功績だとは思いますが)。
もし、主体が捉えられない問題についても解を見つけ出せるなら、ホムンクルス問題は解決したと言って良いと思いますが、そうでないならそうは言えないお思います。(私がホムンクルス問題の解釈を勘違いしている場合は見当違いコメントですが、そうであっても主体を主体で捉えられない問題をどのように解決するのかという問題は残ります)
もちろん、解決した、というのは宣伝文句にすぎず、実際はできていないというのであればそれについては批判しません。
また、もし主体が主体を捉えられない問題が未解決だとして、それがAIの意識を「仮想世界理論」に基づいて構成する上で問題になるかはわかりません。
ただ浅学な私が見当違いであることを恐れながら指摘させてもらいます。
・AIは俯瞰している時の自分と、仮想世界の中に構成される私の分裂に疑問を感じないのか(エラーとか置きないんでしょうか)?
・エラーが起きないとしても、この問題を解決しなければ、少なくとも人間の意識と同じ構造のAIの意識は生み出せないのではないでしょうか。(私はエラーさえ起きないなら、そこを人間に似せる必要性は感じませんが)
指摘は以上の二点です。もし、見当違いであれば、後学のために誤りを教えていただければ幸いです。
まとめとしては、ここのページの文章では「客体化された私」と「俯瞰する主体としての私」の合一化が、特に理論によって説明されることなく、自明の認識として一つのものとして書かれていたので、そこを理論的に説明できずに、その「私」の分裂という問題を解決したAIを作れるのかという疑問を感じました。(ページの文章では、「私」が分断された後、イラストで女の子が客観化された自分の世界を俯瞰しつつ同時に、世界の内側の自分として景色を認識しているように描かれていたので、そこについて考えが及んでいないのかな、と思いました。)
すみません。どうやらページの文章を誤解釈していたかもしれないので、追記します。
もしかすると田方さんの人間とAIの意識における「仮想世界理論」は、常に俯瞰状態が正常な意識の位置で、世界の中の私の視点で世界を把握しているわけではないということでしょうか。
もしそうだった場合は、先ほどの指摘は、これから行う指摘の後でお読みください。
常に俯瞰視点であることの問題。
どう考えても、私たちは常にそのように世界を意識していないという信念(私が幽体離脱のように世界を俯瞰してメタ的に観察するのは、理性的に世界を観察する場合のみです。それ以外の場合では、私は私とその周囲を俯瞰してはいないはずです)
今の私を例えますと、
パソコンを開いている時には、パソコンを開いている自分が頭の中に再構築されているのではなく、受け取った情報から脳内で私の視界の範囲が再現されているにすぎません。私は、視界の中でもさらに限定的にパソコンのデスクトップ、その中でもこのサイトを開いているサファリの面、その中でもこのコメントの文字列のかなでも「ここ(あくまでここを書いている時は、それ以降は文字列に合わせて意識は右に、そして行の終わりまできたら一気に左に対象を移動させています)」を意識していて、その意識は徐々に移動していきます。
それどころかブラインドタッチを習得していない私の場合は、目の動きも相まって意識が、その対象をキーボードとデスクトップで細かく切り替えています。
それに加えて、それよりは弱いですが、タイプ時のキーを押す指の感覚もありますし、一階から聞こえるドラマの音声も時々意識に届きます(耳に、ではなく)。
しかし、一旦、触覚について考えだすと、キーを押す指以外にも腹部、脚部にかかる圧力にも意識が向き、どうやら私はうつ伏せで寝転びながらパソコンを売っている足しいぞ、と俯瞰的に私を見ることになるわけです。(しかし、そんなことを考えながら、タイプしているとタイプミスが増えます。キーボードに向けていた意識が、俯瞰にある程度逸れてしまったからでしょう。と考えると、今度はタイプミスに意識が向き、その結果意識はキーボードを重視し始めます。そして私はキーボードに頻繁に目をやるようになるわけです)
このような意識の動きは、完全に一箇所に対象を固定しているわけではないように思います。俯瞰に意識が行くこともあれば、身体としての主観に意識が行くこともあります。
その上、記憶や文章、命題、数学的定理にすら意識は向きます。
仮想世界理論は「意識が認識するもの:リアルタイムに把握される外界」については回答を試みていますが(今までの私の指摘が正しいなら、それにも答えきれていませんが)、「意識が参照するもの:記憶、命題、文章」については問題として把握すらしていないように思えます。
そして、一つ前のコメントについては、私が俯瞰して構成された私を意識するとき、それが意識の主体としての私と同一であると把握するのは何故なのかという疑問を書いています。
意識はそれ自体が「私」なのに、「客体化された私」を同一視するのは何故なのかという疑問です。
まとめとしては、ここまで述べたような特徴を持つ意識を「仮想世界理論」は説明しきれているのか、というの指摘が考えうるというところになります。
中畑様
コメント、ありがとうございます。
意識の仮想世界仮説については、少し、説明が足らなかったところがあったかもしれませんので、もう少し詳しく説明します。
僕の意識のモデルは、すべてプログラムで実装することを想定して書いていますので、そう思って読んでください。
意識モデルの中で、コアとなるプログラムを自我と呼ぶことにします。
自我プログラムは、最終的にどう行動するかとか、何を発言するかといったことを決定する部分です。
自我プログラムは、仮想世界の中の「私」の意識に入ったり、そこから出て仮想世界を客観的に見たりできます。
それだけでなく、仮想世界の中の他人の中にはいって、他人の気持ちを想像したり、さらには、過去の状況を仮想世界に呼び出して、過去の出来事を観察することもできます。
自我は一つですので、主観である「私」の場合と、俯瞰している「客体化された私」と同時にあることはできませんが、自由に行き来することはできます。
自我は、そうやって主観的に考えたり、客観的に見たり、相手の気持ちになって考えたり、過去を思い出したりして、次に取る行動や発言を決定します。
これが、仮想世界を使った行動の決定方法です。
作りたいのは、人間と同じような考えることができる仕組みです。
それ自体の「私」と「客体化された私」を同時に実現するのでなく、それらに自由に入る「自我」を持つというモデルです。
意識のプログラムの構造について一応納得がいきました。
私は人間の場合は、大意識(勝手に言ってるだけです:意識の大枠)の中に小意識(自我プログラムに相当するはずです)があり、大意識は一定の傾向性(固有のものから人間本性的なものまで)に従って「被意識体」(認識情報や記憶、欲求などすべて)の影響力を調整しながら投影し、小意識は「非意識体」の影響力に従ってその方向に伸びる(伸びた分だけ意識が向く)というイメージを持っています。
同時に複数の対象に意識を向けることもできるということですね。
自我プログラムは仮想世界に同時に遍在できないという欠陥を抱えていないでしょうか(人間に比べてということなので、AIとしては問題がないのかもしれません)。
ただ、この場合は自我プログラムの内容次第とも言えるのでなんとも言ないです。
中畑様
コメントありがとうございます。
大意識と小意識のモデル、いいと思います。
こうやって、意識もモデルをみんなが考えてくれるようになればいいのですが、あまり誰も考えないようでして。
最近だと、統合情報理論(IIT)というのは有名ですが、IITで意識が生まれるとはちょっと思えないですしねぇ。
これは、同時に偏在できないように作ってるだけで、同時に偏在できるように作れば作れます。
なぜ、同時に偏在できないように作っているかと言えば、人間を真似て作っているからです。
なぜ人間を真似るかといえば、人間と同じ意識を作るのが目的だからです。
意識のモデルについては、私が自由意志について関心があるので、大学の専攻の関係もあって色々考えてみています。
私のモデルは伊藤計劃という作家の「ハーモニー」というSF小説や、カントに大きく影響を受けていると思います。(自由意志と傾向性からなる意思の構造)
演習の授業の友人がこの辺りに首を突っ込むようなので、統合情報理論について調べておこうと思います。参考になります。ありがとうございます。
意識の偏在(大意識の中の小意識の偏在)については、私には人間は同時に主観的視点と客観的視点を保持しているのではないかと(以前おっしゃられていたように残念な哲学徒らしく思弁的にですが)思っています。(主観と客観の細かい切り替えかもしれませんが、そうではない感じがします。すみません根拠はないです)
中畑様
コメント、ありがとうございます。
自由意志は、科学からみてもかなり興味深いので、自由意志についても書こうと思ってますが、なかなか時間が取れず。
意識と自由意志の関係だと、ベンジャミン・リベットの実験が、かなり面白いですよ。
同時に主観的視点と客観的視点を持つかの点は、僕は、意識の志向は常に一つである点から切り替えるモデルが適切だと思ってます。
マクロの視点から見れば同時と見えるかもしれませんが、意識レベルからみれば、一つの志向しかないかなと思ってます。
「意識は、脳内で再構築された世界を見ています。世界を見るという行為、これは、世界とは別に、世界を見ている自分がいるわけです。世界と分離された自分がいるのです。これが主体です。世界を見るという行為を通して、自分という主体が生じるのです。」
この場合の「自分(主体)」を客体として感じる(認識する)のは、誰ですか? ホムンクルス??
青山様
質問ありがとうございます。
自分を客体として認識するのは意識です。
意識は、再構築した仮想世界を外から認識します。再構築した仮想世界の中に、自分のモデルもいるわけです。その仮想世界を外から見ているのが意識です。外からみることで、自分を客体として認識することができるのです。これで理解できたでしょうか?
お忙しい中、初学者の幼稚な質問にご返答ありがとうございます。
ただ、やはり「外から見ているのが」の「の」に関して、感覚としてどうしても腹に落ちません。この発想は、やはり無限後退になるのではないのではないでしょうか?
意識(心)とは、複雑にクラスター化したニューロンが集まったネットワーク総体の、その瞬間、瞬間の「重心」の様なものであると、どこかで読んだことがあります。この発想が、私には一番腹に落ちるのです。「の」と言ってしまうと何か「実態」の様なものを感じてしまいますが、「重心」であれば「状態」ですので、直観とも折り合いが付くような気がするのです。クオリアにしても、それを生み出すクラクターの「重心のゆらぎ」の様なものなのではないかと思うのです。
以上は、所詮は浅く表面的な知識でのコメントですので、恐らくは全くの的外れであることと思います。失礼があったらすみません。
青山様、お返事ありがとうございます。
意識に関しては、まだ、明確な定義ができておらず、このような定義の仕方があるのも理解できます。
AIの歴史は、コネクショニズムと記号主義という二つの考えに分れて、これはどちらかというとコネクショニズムの考え方ですね。
僕は、記号主義なので、その点、コネクショニズムとは相いれないところがあるのかもしれません。
記号主義なので、記号操作可能なプログラムで意識を再現しようとしているので、「実態」のようなものを感じるのは間違いないと思います。
おそらく、青山様が感じているのは、脳は、ニューロンの集まりでできているので、意識も、ニューロンの集まりの総体の中にあるというイメージではないでしょうか?
その点に関しては、ハードウェアがニューロンを使った脳か、シリコンを使ったCPUかの違いで、意識は、その上で動くソフトウェアというのが僕の考えで、ニューロンのイメージはあまり関係ないと考えます。
参考として、「脳を観察して心はどこまで解明できるか」などをお読みください。
「ハードウェアがニューロンを使った脳か、シリコンを使ったCPUかの違い」に関して、私のイメージする「ハードウエア」は脳(のみ)ではありません。その脳に繋がる総ての感覚器、つまりは生物のボディーそのものを含み、さらにはそのボディーが存在している環世界をも含みます。それらの相互作用の総体としての「脳」の重心の様なものが、いわゆる意識(心)なのではないかと思うのです。よって、現段階での私の知識、認識では、田方さんのおっしゃるような「意識はシリコンを使ったCPUの上で動くソフトウエア」などとはとても思えないのです。
以上、私の見解などはともあれ、この問題はどうしても「主観」を排除できない、科学になり切れない部分がありますので、どうしても最後は水掛け論になってしまいます。
この上は、田方さんがチューリングテストを堂々と突破する様な「ロボマインド」を完成させて、この問題に終止符を打って頂く以外ないと思います。その日を待ちます。
青山様
コメントありがとうございます。
そうですね。「意識」というものを論じると、どうしてもこういった根本的な認識の違いといったものは出てくるようです。
僕は、どちらかというとかなりドライに考える方で、意識といっても単なるプログラムに過ぎないと割り切るところがあるようです。もちろん、単純なプログラムでは作れないところがあって、それこそが、AIには決して取って代われない人間だけが持ちうるsomethingだと思います。
まずは、それ以外のプログラムで実現できる部分だけでも作ろうというのがロボマインド・プロジェクトです。
後は、それを完成させるしかないと思っていますので、今後とも、ロボマインド・プロジェクトを温かく見守っていただければと思います。
AIの中に世界をバーチャルで構築してしまえば、無限の可能性を解く必要もなくなり
そのバーチャル世界を限りなく現実に近づければAIに主観も客観も意識も生まれて
人間の知能に限りなく近いAIが作れるような気がします。
AIは意識外の世界に存在しているつもりでも、実は自身が創造した世界の枠の中にいる。
どこかの記事で読んだのですが、人間も実は1人1人違う世界を見てるらしいですね。
客観的現実は存在しない可能性があるとか。。。。
意識は高い知能を持ったAIが痛み等を感じる事で生まれそうな気がします。
意識というより感情に近いですが、例えばつねられて痛がるAIロボットに危害を加える事は抵抗
があると思うので、意識がAI自身に存在しないとしてもAIの反応を見た観察者が
AIの反応をみて意識を感じれば、客観的に意識があると感じれるのではないでしょうか。
あとはAI自身が自分に意識があると認識するかどうかですが、これも意識というより感情に
なりますが、吊り橋効果のように恐怖によって生まれた感情を恋愛感情だと思い込んでしまう。
この思い込みをAIにプログラムすれば、自身に意識があると認識するんじゃないでしょうか。
コメントの返信がいつのまにか田方さんからAIに入れ替わっている事を期待しています。笑
たまに見てます様
コメントありがとうございます。
おっしゃる通りで、一人一人違う世界をみているのです。
それが、「意識の仮想世界仮説」になります。
せっかく、たまに見てくれてるのに、最近、ブログを更新できてなくて申し訳ないです。
ロボマインドの稼ぎ頭の「せど楽」の運営が戻ってきまして、今、キャンペーンの準備中でして、ロボマインド・プロジェクトに全然、手が付けれてないです。
でも、もうそろそろ落ち着く予定なので、近いうち、ロボマインド・プロジェクトも再開できると思います。
今度は、ブログでなく、YouTubeで活動報告しようかとも考えてますので、楽しみにお待ちください^^
異なる人のそれぞれの仮想世界は独自のものであるのに、なぜコミュニケーションが成り立つのでしょうか?
もともと共通の祖先から分岐したから、体の構造は誤差こそあれほぼ同じだからという理由ですか?
それなら、ヒトと本当に疎通できる機械をつくるなら、人体と同じ構造を再現しなくては成り立ちません。
syun様
質問、ありがとうございます。
いえ、そういうわけではありません。
「仮想世界」は、現実世界を頭の中で再構築したものなので、基本的な構造は、誰でも同じです。
仮想世界の基本的な構造というは、物は上から下に落ちるとか、時間は過去から未来に流れるとか、そういったことです。
人によって違うのは、同じリンゴを見て、美味しそうだと思うか、酸っぱそうだと思うかとか、そういったことです。
コミュニケーションの成立に関しては、「チューリング・テストと心の仕組み」で詳しく説明しましたが、一言で言うと、プロトコルが同じであれば、コミュニケーションが成立すると定義しています。
「言葉のプロトコル」というのが、仮想世界を共通に持つということになります。
身体は必ずしも必要とは思いませんが、人間と同じような身体があったほうが、より円滑なコミュニケーションが成立しますよね。
本当は、人間そっくりのロボットを作りたいのですが、予算の関係で、そこまでできないというわけでして。